2020/01/30 04-Pymysql使用
本文共 2866 字,大约阅读时间需要 9 分钟。

mysql connector支持多种语言链接 MySQLdb是python的一个库,到了3.0不继续开发了 pymysql现在支持比较广泛,兼容mysqldb

 首先需要基于tcp编程,创建链接,发送心跳包之类的,你发的结果集,对方需要解析,数据库写的sql语句并不在客户端做任何校验,连接到对方需要connection
首先需要基于tcp编程,创建链接,发送心跳包之类的,你发的结果集,对方需要解析,数据库写的sql语句并不在客户端做任何校验,连接到对方需要connection 
 查看源码connect
查看源码connect  调用pymysql的connect实际上调用的是connect函数
调用pymysql的connect实际上调用的是connect函数
 这些就是帮助,host主机,ip,用户,密码,端口
这些就是帮助,host主机,ip,用户,密码,端口
 host主机,ip,用户,密码,端口 ping方法一旦失败,则直接抛出异常
host主机,ip,用户,密码,端口 ping方法一旦失败,则直接抛出异常  ping其实没有返回值,返回值是none,reconnect是重新链接
ping其实没有返回值,返回值是none,reconnect是重新链接  一旦重连,就编程false,不然是反复重连
一旦重连,就编程false,不然是反复重连  重连失败就抛出异常
重连失败就抛出异常  现在测试user表
现在测试user表 



 cursor会创建一个cursor对象 外面一般双引号,里面用单引号
cursor会创建一个cursor对象 外面一般双引号,里面用单引号 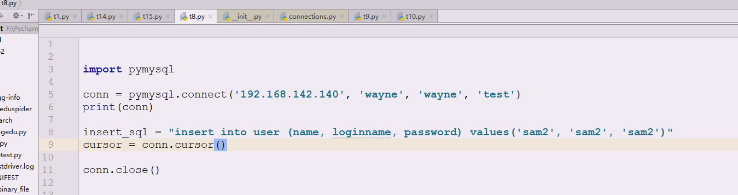 现在可以执行sql,execute,操作完sql后,不用也需要关闭close()
现在可以执行sql,execute,操作完sql后,不用也需要关闭close()  运行一下
运行一下  因为代码里没有提交,需要强制刷新一下
因为代码里没有提交,需要强制刷新一下  递增就变成4 了
递增就变成4 了  但是数据确实没进来,因为现在还没对数据库进行提交,所以刚才的事务改变不作数
但是数据确实没进来,因为现在还没对数据库进行提交,所以刚才的事务改变不作数  再次执行
再次执行  但是3跳过去了
但是3跳过去了
 就算删除一行,主键也是在最大值递增的,所以主键可以不连续
就算删除一行,主键也是在最大值递增的,所以主键可以不连续 现在是唯一键出现问题,loginname不允许冲突
 再次执行一遍
再次执行一遍
 现在插入这个数据
现在插入这个数据  但凡保存下来,主键就变成了101,主键自增的情况下也可以自己往里面塞ID
但凡保存下来,主键就变成了101,主键自增的情况下也可以自己往里面塞ID 所以插入数据有可能失败,就需要用到try,你打开的资源就需要关闭
所以插入数据有可能失败,就需要用到try,你打开的资源就需要关闭  链接的时候也可能出现问题,也可以用try
链接的时候也可能出现问题,也可以用try  cursor也是一样的,会出问题
cursor也是一样的,会出问题  现在试试查询,纯查询不会对表数据进行影响,一般不做事务提交和回滚,但游标还是一种资源,该关闭还是需要关闭。游标的真正作用是对结果集进行处理
现在试试查询,纯查询不会对表数据进行影响,一般不做事务提交和回滚,但游标还是一种资源,该关闭还是需要关闭。游标的真正作用是对结果集进行处理 
执行返回的结果告诉你,只是成功影响了几行
 这时候还需要用cursor,对结果集进行处理,返回的是一个tuple,元组
这时候还需要用cursor,对结果集进行处理,返回的是一个tuple,元组  拿一行,这个游标就动了一下,指向 了第二行的tom1
拿一行,这个游标就动了一下,指向 了第二行的tom1
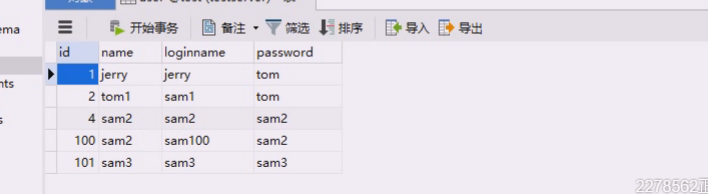 还提供了fetchmany(参数)
还提供了fetchmany(参数) 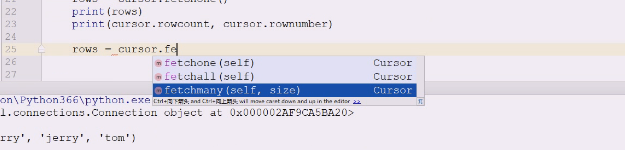 用一个容器把这两行装在一起,2表示,再拿两个,用容器把这个两行装起来了
用一个容器把这两行装在一起,2表示,再拿两个,用容器把这个两行装起来了 试试fetchall
试试fetchall  cursor是管结果集的,数据并不能从exectute里拿到,需要借助fetch系列的函数, fetchone拿一个 fetchmany,指定拿几个 fetchall,拿所有 大多数情况下都用fetchall,结果如果太多用limit(sql语句控制),这里的fetch说明结果已经从服务器端查好之后,形成一个结果,把这个结果通过链接推送到客户端了,这样耗费了很多资源 所以select语句查询的时候建议加where和limit,查询是最容易出现效率低下的地方
cursor是管结果集的,数据并不能从exectute里拿到,需要借助fetch系列的函数, fetchone拿一个 fetchmany,指定拿几个 fetchall,拿所有 大多数情况下都用fetchall,结果如果太多用limit(sql语句控制),这里的fetch说明结果已经从服务器端查好之后,形成一个结果,把这个结果通过链接推送到客户端了,这样耗费了很多资源 所以select语句查询的时候建议加where和limit,查询是最容易出现效率低下的地方 游标到头,处理完了
现在拿到的数据没有字段名
 查看cursor里面的源码调用 因为链接只管链接,数据集操作还需要找cursor
查看cursor里面的源码调用 因为链接只管链接,数据集操作还需要找cursor
 如果cursor等于none就返回,self.cursorclass(self)实例化
如果cursor等于none就返回,self.cursorclass(self)实例化 cursorclass用这个变量
cursorclass用这个变量  这个缺省值是一个类,autocommit=false,不会自动提交,一般都是手动提交,因为由你判断此次操作是否成功,如果成功就commit,失败就回滚,所以要写try语句
这个缺省值是一个类,autocommit=false,不会自动提交,一般都是手动提交,因为由你判断此次操作是否成功,如果成功就commit,失败就回滚,所以要写try语句 
 cursor类里面还管理一个链接
cursor类里面还管理一个链接 还有一个mixin类,支持dict字典
还有一个mixin类,支持dict字典  传进来的如果是不是none,就需要初始化构造,里面只需要类
传进来的如果是不是none,就需要初始化构造,里面只需要类
 外面列表里面字典,下面需要遍历就很简单,如果不想立即返回结果,就可以使用一个个yield出去,python3鼓励使用生成器
外面列表里面字典,下面需要遍历就很简单,如果不想立即返回结果,就可以使用一个个yield出去,python3鼓励使用生成器


 一旦出错可以回滚
一旦出错可以回滚 
 多条sql语句必须使用;分号间隔
多条sql语句必须使用;分号间隔 现在批量插入数据
 现在就有一堆数据
现在就有一堆数据  一般执行顺序,就是建立链接,获取游标,执行sql,提交事务,释放资源
一般执行顺序,就是建立链接,获取游标,执行sql,提交事务,释放资源 

 带列名查询需要用到DictCursor,mixin的子类
带列名查询需要用到DictCursor,mixin的子类 
sql 注入攻击

 现在查询的就是id=1,没有问题
现在查询的就是id=1,没有问题 这样查本来是查不到数据的,关键是pwd如果没有做特殊处理
这样查本来是查不到数据的,关键是pwd如果没有做特殊处理  这样就凑成了,or后面恒等就把所有的用户名和密码都取出来了
这样就凑成了,or后面恒等就把所有的用户名和密码都取出来了  客户端无论进行什么样的尝试,都不要告诉对和错,得到的信息最少最安全,sql注入攻击最常用的就是登录这块,所有注入攻击解决方案都一样,是参数化查询
客户端无论进行什么样的尝试,都不要告诉对和错,得到的信息最少最安全,sql注入攻击最常用的就是登录这块,所有注入攻击解决方案都一样,是参数化查询
 使用这种参数化查询
使用这种参数化查询 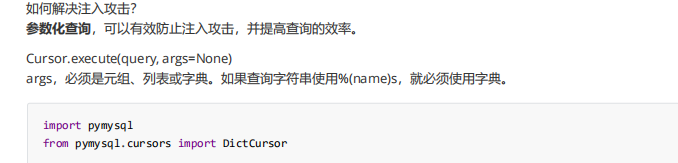
 现在这样参数化可以查询出来
现在这样参数化可以查询出来  现在改成参数化查询,能查是能查,把原有东西非法的部分截断了,原有sql语句 空格就是间隔,所以通过参数化查询,就可以解决注入攻击
现在改成参数化查询,能查是能查,把原有东西非法的部分截断了,原有sql语句 空格就是间隔,所以通过参数化查询,就可以解决注入攻击 参数化查询还能解决批量查询的问题
参数化查询还能解决批量查询的问题 循环起来,缺的参数从下面拿
 查看是如何实现的
查看是如何实现的  每一次迭代生成一个数据
每一次迭代生成一个数据  之前是把参数凑成一条语句,到上面把语句一句句执行
之前是把参数凑成一条语句,到上面把语句一句句执行  所以还是可迭代对象迭代了,也是挨个一个个执行
所以还是可迭代对象迭代了,也是挨个一个个执行  参数化查询可以有效解决sql注入攻击的问题,参数化查询可以进行sql语句的缓存,数据库服务器,会让sql语句进行缓存,编译只对sql语句进行编译和缓存。 编译过程,需要词法分析,语法分析,生成AST抽象语法树,用抽象语法书再进行优化,生成执行计划等过程,所有的编译环节都需要做这个事情,编译的过程是比较耗费计算机资源的 参数化查询,只要传入的参数一样,如果有缓存可以在数据库服务器里的缓存能找到,就可以直接用缓存,(缓存的是语句,不是结果) 但是一般性能少还是比较趋向于sql语句的写法问题
参数化查询可以有效解决sql注入攻击的问题,参数化查询可以进行sql语句的缓存,数据库服务器,会让sql语句进行缓存,编译只对sql语句进行编译和缓存。 编译过程,需要词法分析,语法分析,生成AST抽象语法树,用抽象语法书再进行优化,生成执行计划等过程,所有的编译环节都需要做这个事情,编译的过程是比较耗费计算机资源的 参数化查询,只要传入的参数一样,如果有缓存可以在数据库服务器里的缓存能找到,就可以直接用缓存,(缓存的是语句,不是结果) 但是一般性能少还是比较趋向于sql语句的写法问题 


 需要有上下文管理这些资源,比如游标,链接, 这样cursor可以拿来直接用
需要有上下文管理这些资源,比如游标,链接, 这样cursor可以拿来直接用  conn的exit里面没有关注cursor,离开的时候没有管
conn的exit里面没有关注cursor,离开的时候没有管  所以离开的时候cursor主动关闭一下,cursor一旦关闭就不能使用 了
所以离开的时候cursor主动关闭一下,cursor一旦关闭就不能使用 了 
 先关闭了但是还可以使用指针,cursor关闭是把链接一下关闭。但是数据集没有
先关闭了但是还可以使用指针,cursor关闭是把链接一下关闭。但是数据集没有  后面再执行查询,就排除异常
后面再执行查询,就排除异常 执行一次拿到结果,还可以再次执行,再拿到结果,使用cursor可以反复操作数据库,用完记得关闭
执行一次拿到结果,还可以再次执行,再拿到结果,使用cursor可以反复操作数据库,用完记得关闭 cursor有打开,有关闭,试试是否可以用with,查看源码
cursor有打开,有关闭,试试是否可以用with,查看源码  退出时,删除所有异常,把自己关闭,
退出时,删除所有异常,把自己关闭,  链接不会关闭自己,只会提交和回滚,链接在进入的时候会返回cursor给你使用,cursor用with进入enter,返回自己,等于什么都没做。,离开cursor一定会保证当前cursor的close
链接不会关闭自己,只会提交和回滚,链接在进入的时候会返回cursor给你使用,cursor用with进入enter,返回自己,等于什么都没做。,离开cursor一定会保证当前cursor的close  链接的enter是返回的一个cursor对象,退出的时候做一些判断,失败回滚
链接的enter是返回的一个cursor对象,退出的时候做一些判断,失败回滚 


 把这一段代码写到try语句块,finally,conn。close,一定保证close一定关闭,因为cursor没有在with语法退出的时候关闭,需要手动关闭,保证关闭就需要try
把这一段代码写到try语句块,finally,conn。close,一定保证close一定关闭,因为cursor没有在with语法退出的时候关闭,需要手动关闭,保证关闭就需要try pymysql是数据库访问的基础,效率不
pymysql是数据库访问的基础,效率不 转载地址:http://txzgn.baihongyu.com/
你可能感兴趣的文章
6-1 数组工具类的设计 (16分)
查看>>
7-1 程序填空题2 (12分)
查看>>
7-2 程序改错题3 (12分)
查看>>
7-3 计算年龄 (20分)
查看>>
7-3 利用集合类排序 (12分)
查看>>
Swing开发之JComboBox篇
查看>>
JVM内存的设置(解决eclipse下out of memory问题)
查看>>
sscanf 总结
查看>>
android图片特效处理之图片叠加
查看>>
windows 使用GetLocalTime 和GetSystemTime 所获得的时间不同
查看>>
Android进阶2之图片缩略图(解决大图片溢出问题)
查看>>
Android学习笔记进阶19之给图片加边框
查看>>
Android学习笔记进阶18之画图并保存图片到本地
查看>>
Android学习笔记进阶20之得到图片的缩略图
查看>>
Html制作漂亮表格
查看>>
android图片特效处理之怀旧效果
查看>>
android图片特效处理之锐化效果
查看>>
android图片特效处理之光晕效果
查看>>
JSP之JDBC操作Sql Server数据库
查看>>
Android学习笔记之RadioButton RadioGroup
查看>>